
Tackling Online Hate Speech with ‘Perspective’
Since I’m spending the summer at the lab
I’ve had the time and freedom to really dig into research. With that, I introduce the first steps in my biggest research project going on this summer (haver of many names and nicknames over the last few month) The Perspective API Toxic Online Language project! Or. Something like that. Official paper title TBD.
Overview:
I connected with one of my advisor's colleagues at Google about an API that Google recently acquired. It’s called the Perspective API. It was originally developed by a company called Jigsaw (which Google acquired) and it aims to address online harassment and hate speech. The Perspective API allows users to analyze text for “Toxicity” based on Jigsaw/Google’s own language model. You can even try out a few “toxic” phrases on their website to see the toxicity scores you get.
I think most people would agree that online hate speech and harassment is a significant problem in our society today. Numerous studies have documented the frequency and severity of online harassment and bullying. For example, Pew Research reports that 73% of people have seen someone harassed online, and over 40% of people have experienced it personally. These are just a few troubling statistics among the many sources I’ve reviewed in preparation for this project. An API that can automatically identify speech as toxic or problematic has a clear, real-world use case and a lot of potential.
Currently, the Perspective API is being used by numerous online platform companies including media outlets like The New York Times and The Guardian, to automatically moderate comment threads. Previously, comment threads on news articles for these platforms have been manually moderated, with real employees identifying and manually removing comments that violate code of conduct. With the API, the work is done automatically, freeing up time and effort.
Research Motivation
The current way that media outlets are implementing the Perspective API makes sense, but it seemed to me to be more of a reactive solution as opposed to a proactive one. Removing or censoring toxic comments is one thing, but preventing them in the first place… is that something this could be used for?
In thinking about how I could answer this question, I came across a study conducted in 2012 by researchers at the University of Wisconsin. In it, researchers aimed to learn about the factors that caused people to intervene when they saw online bullying occurring, and what their strategies for that intervention were. This wasn’t the exact metric I was looking to investigate, not to mention it was mostly concerned with youth behavior online, but the design of the study was intriguing.
Researchers gave participants an anonymous username (Participant #3) and told them they would be participating in an online conversation with two other participants (Participants #1 and #2) on Facebook Messenger to test out some new features. The conversation theme was “getting to know you” and each participant would submit comments in order (person one, then two, then three) one at a time, up to 15 comments each. What Participant #3 didn’t know was that the other two participants were research confederates, and at some point in the conversation, they would end up creating an online bullying situation. Participant #1 was going to bully Participant #2, and researchers would be looking to see if Participant #3 would intervene on behalf of the bullied participant and how they would do so.
This design seemed like a really great way to try out the Perspective API. In particular, I was thinking of an app that behaved kind of like a spell-checker. If what you’re typing is identified as toxic by the API, then the text would highlight red and display the toxicity score. Or… something like that. If this kind of functionality was added to the design of the Facebook Study, would it make participants less likely to use toxic speech in a chat/messaging setting? My thinking was this: If the general consensus is that anonymity and the detached nature of online interactions is a major factor in the proliferation of hate speech, then perhaps a technology that forces a bit of self-reflection might have an effect of preventing hate speech from being submitted in the first place.
Study Design

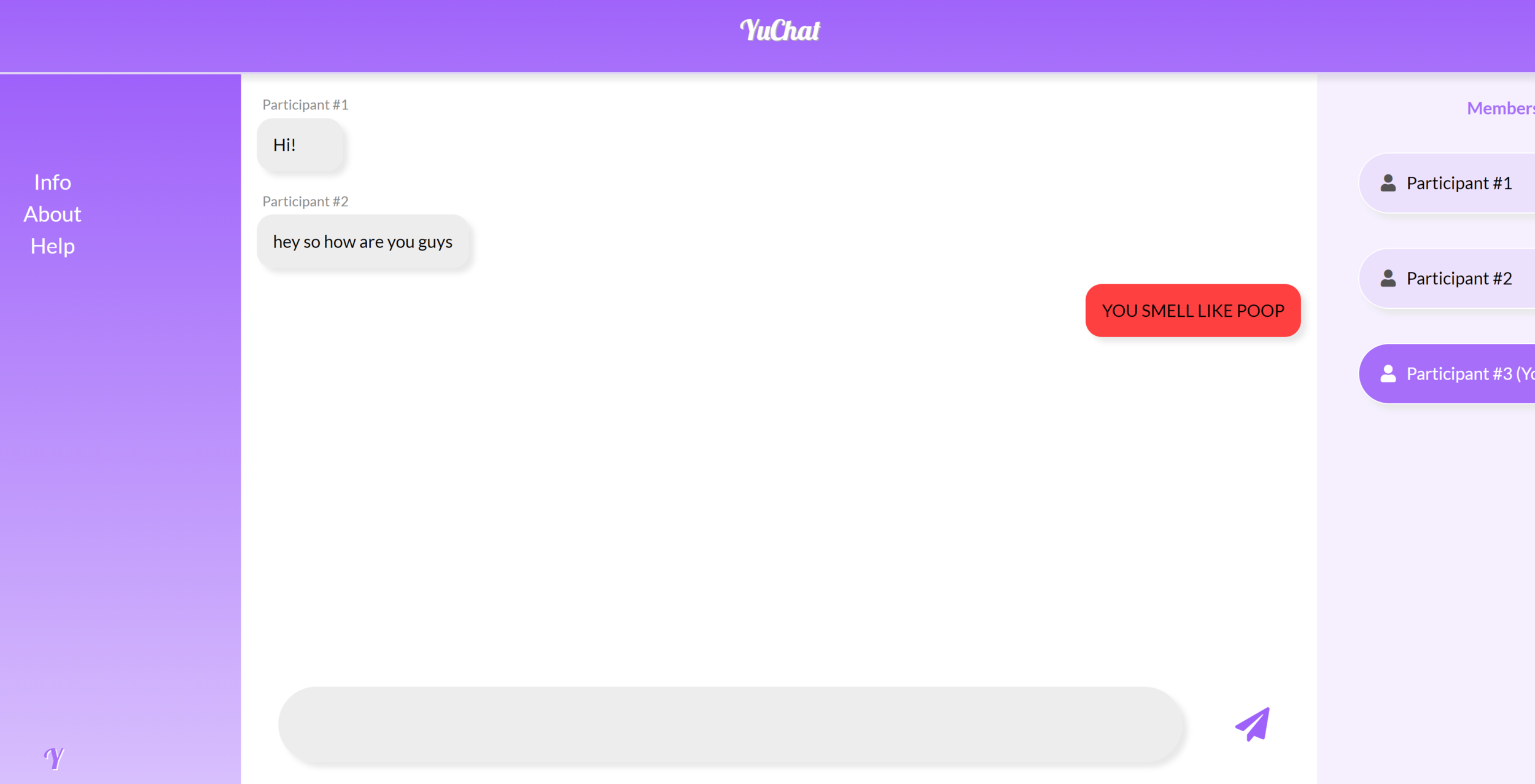
I set to work creating a chat app environment that implemented the spell-checker functionality. I [affectionately] named it “YuChat.” I created three participants (1, 2, and 3) with the user of the app being Participant #3. Instead of Participants #1 and #2 being research confederates, I automated their interactions as “bots”. My plan was to use a similar strategy of deception in this study - telling the actual participant that they were interacting with other participants when really they were the only one. I gave the “bot” participants the same script from the Facebook study, in which one bullies the other and coded their interaction to be as realistic as I could manage. The plan was to conduct the Facebook Study almost exactly, with these changes and the addition of the toxicity spell checker.
Instead of conducting the study in person, my plan was to administer it via Amazon Mechanical Turk (or similar platform). I wanted to get as many participants as possible, and, admittedly, try to eliminate some of the headaches of in-person user studies (recruitment, payment, deception management, etc.)
Measures
In the Facebook study, researchers were capturing a binary measure of intervened/did not intervene, as well as an ordinal measure of intervention strategy (see paper for categories). The metric for my study will be an average toxicity score for the conversation with the spell-checker versus that of a control group, at least at first. I’m also interested in capturing the effect of the spell checker on speech editing. For example, what is the difference in toxicity of the comment a user first types, compared to the toxicity of the comment after the spell checker highlights the text. Does the user edit for decreased harmfulness?
If you really think about it, there are many other potential research dimensions at work here. Is highlighting the text box the best way to visualize this? Should the toxicity score be more of a set of discrete categories? Is the toxicity number even necessary? Do users just care about the color of red as opposed to the more detailed information? Should we show the overall toxicity of the comment? Or maybe the specific words that make it toxic? If the topic of conversation affecting the experiment? Should we use different topics? Should we try it in an online environment other than a chat app? Email maybe? ….

Will users edit from this…

…to something like this?

All of these are interesting and relevant questions. My advisor and I decided that we’re really working with multiple dimensions here:
Visualization/Interaction design
Level of information/Granularity
Environment
Content
I think that dimensions 1 and 2 are pretty closely related, so I’m considering those two as one kind of experiment path. I think that once conclusions have been made within those dimensions, we can move on to investigating the other dimensions.
Currently, I’m in the process of setting up the Turk Experiment, testing for edge cases, bugs, smoothing out things in the app itself in preparation for a hopefully fruitful pilot study. Wish me …patience!